Data
-
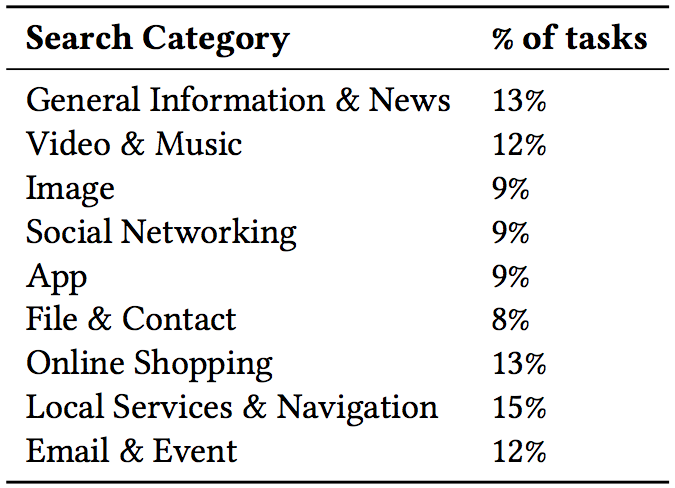
Cross-App Mobile Search Tasks: In the first crowdsourcing task, we described the category of search, giving the workers a handful of general examples. Furthermore, we also asked them to give us the context and background of their search, as well as the queries and the apps they used to do the search. Finally, we provided a complete example of a valid answer. We launched this job for most of search categories listed in the below.
"I was searching for a new refrigerator to buy. The first thing I did was search for the best refrigerators of 2017 and then narrow down my search for exactly the type of refrigerator that I was looking for..."
Then, we used this answer to define a more general search task:"Consider one of the oldest appliances in your home. You have been thinking of changing it for a while. Now, it's time to order it online."
Moreover, we used a few tasks from the TREC Robust track for general web search category. Overall, the tasks can be categorized into two classes: 1) specific tasks where we ask users to find information about a specific information need, 2) generic tasks where we ask users for a query that would satisfy an information need they have (or had before doing the HIT). Since the nature of some apps such as Notes and File Manager are very personal, it is difficult to define specific tasks that would make sense to all workers. Therefore, we decided to simply ask them to report their latest queries in such apps, or a query that they would submit to these apps at the time of the HIT. Here is an example of such tasks: Consider the apps you usually use to manage your notes or files. What was your latest file or note search query on your smartphone?
-
Cross-App Mobile Search Queries: The second crowdsourcing task consisted of 206 individual search task descriptions, mostly extracted from the answers we got from the first task. In the definition of tasks, our aim was to cover various aspects of mobile information seeking. Here the HITs started with an introduction of the task, followed by the steps workers had to follow. We asked the workers to read the search task description carefully and assume that they wanted to perform it using their own mobile device. Then, we asked them to select one or more apps from a given list. Alternatively, they could type the name of the app they would choose for that search task. We provided an auto-completion feature for entering the apps' names in order to make it easier for the users to type the name of their favorite apps. The interface we designed for this HIT is shown in the figure below:
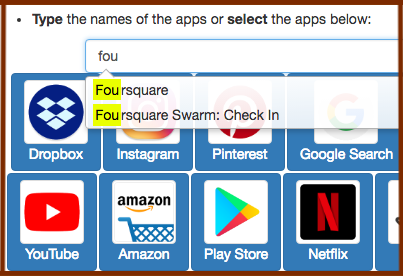
Note that, in the published paper [1], we considered the selection of Google Search and Google Chrome identical, because many workers could not distinguish between these two apps. However, in the released dataset we keep these two apps as they were selected by the workers. Below, we can see that the majority of the queries were targeted to apps other than Google Search: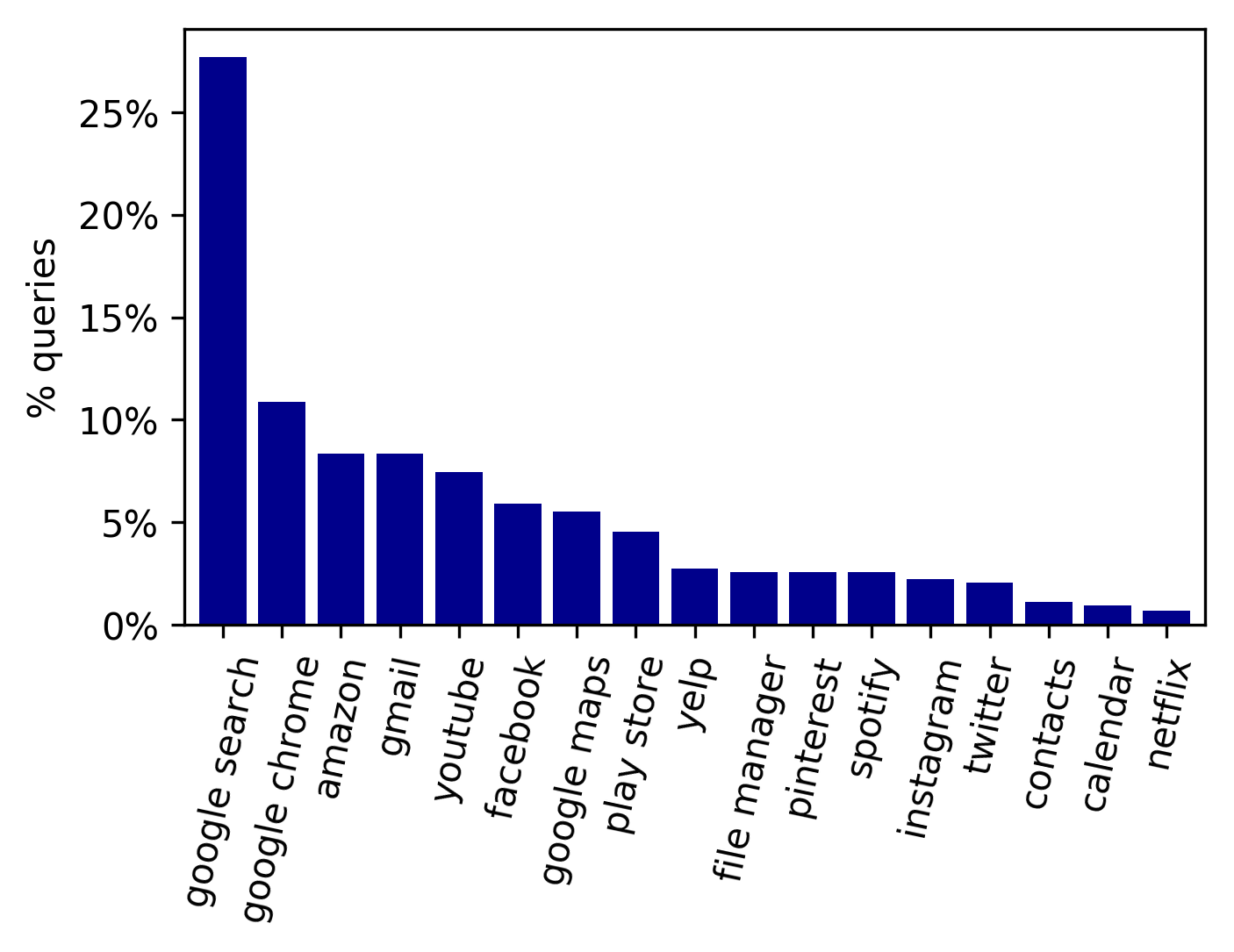
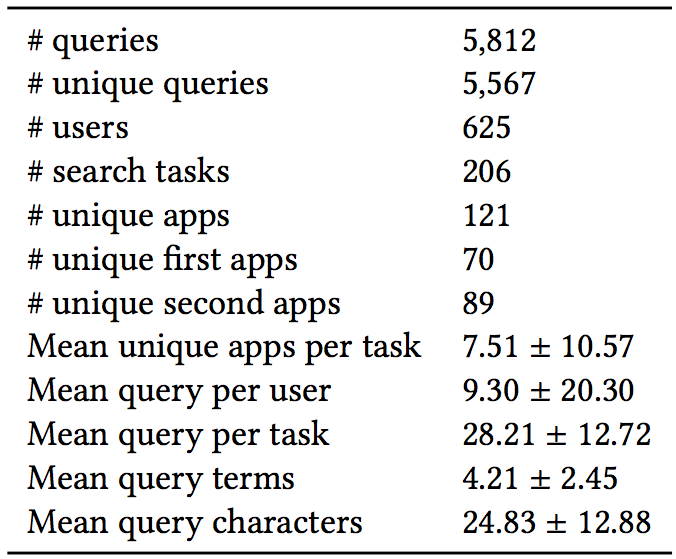
We have made the collection publicly available for research purposes. The released data consists of the tasks that we defined through the first set of HITs as well as user queries in the second set of HITs, together with their corresponding ranked list of apps. The data can be used to study how users are engaged in searching with different apps. Also, the release of the defined tasks provides the opportunity to conduct a similar study in a lab setting on participants' mobile phones and compare the findings with this work. Some general statistics of the dataset can be found below:
UniMobile: a collection of cross-app mobile search queries Download UniMobile
Recent years have witnessed a rapid growth in the use of mobile devices, enabling people to access the Internet in various contexts. More than 77% of Americans now own a smartphone, with an increasing trend in terms of the time people spend on their phones. More recently, with the release of intelligent assistants such as Google Assistant, Apple Siri, and Microsoft Cortana, people are experiencing mobile search through a single voice-based interface. These systems introduce several research challenges. Given that people spend most of their times in apps and, as a consequence, most of their search interactions would be with apps (rather than a browser), one limitation is that users are unable to use a intelligent assistants to search within many apps.
So far, all the studies on mobile information retrieval have focused on a single interface for search (i.e., Google, Bing, etc.). However, we believe that this is no longer the case with the availability of various apps featuring their own search engine. Nowadays, users tend to search for various modalities of information using different apps. As of 2016, the average U.S. user spends 5 hours on mobile devices per day, with just 8% of it spent in the phone's browser. In fact, people spend most of their time (72%) using apps that have their own search feature.
In this data collection, we are particularly interested in providing the first dataset focusing on a unified search framework for mobile devices by collecting cross-app mobile queries as well as their target apps. To this end, we initially asked crowdworkers to explain their latest search experience on their smartphones and used them to define various realistic mobile search tasks. Then, we asked another set of workers to select the apps they would choose to complete the tasks as well as the query they would submit. One of the key takeaway findings is that for the majority of the search tasks, most of the users prefer not to use Google Search. Here, we release the dataset for research purposes. While we release only the query-app pairs as well as their corresponding tasks and workers, more details are available upon request. More details about the dataset is available in our paper [1].
Download
Both parts of the dataset can be downloaded as a single ZIP file here. If you use UniMobile dataset in your next research paper, please consider citing our paper, using this BibTeX file.Note: We only release the query-app pairs as well as their corresponding tasks and workers. If you need more details about the data (e.g., crowdsourcing work time), please contact us. More data is available upon request.
- TaskId: a unique identifier for the task. The same ID is used to refer to the task in the query file.
- TaskDesc: the description of the tasks as they were shown to the workers.
Format
Upon downloading the data, you get one compressed file, containing two files. You can uncompress it using gzip, zip etc. The first file is a CSV file, called tasks.csv, which contains the mobile search tasks. Each row of the CSV file for mobile search tasks has these fields: TaskId TaskDesc
24 Imagine you have a pet at home. Consider something that you would like to buy for her/him. Once you decided what to buy try to find it and order it online.
33 One of your friends is considering plastic surgery and you would like to help her find information about the safety or hazards of plastic surgery. Find information about the safety of typical plastic surgery procedures.
The second CSV file, called mobile_queries.csv, which contains all the cross-app queries workers wrote in response to the tasks, together with their corresponding apps. Each row of the CSV file contains the following fields:
- index: a unique identifier for the row.
- TaskId: the ID of the task for which the query is written for.
- WorkerId: the ID of the worker who wrote the query.
- Query: the query that is written for the given task.
- SelectedAppCount: the number of mobile apps the worker selected, indicating that they would carry out the given task in any of those apps.
- App0: the first app that the worker selected for carrying out the given task.
- App1: the second app that the worker selected for carrying out the given task (left blank if no app was selected).
- App2: the third app that the worker selected for carrying out the given task (left blank if no app was selected).
- App3: the 4th app that the worker selected for carrying out the given task (left blank if no app was selected).
- App4: the 5th app that the worker selected for carrying out the given task (left blank if no app was selected).
- App5: the 6th app that the worker selected for carrying out the given task (left blank if no app was selected).
- App6: the 7th app that the worker selected for carrying out the given task (left blank if no app was selected).
- App7: the 8th app that the worker selected for carrying out the given task (left blank if no app was selected).
- App8: the 9th app that the worker selected for carrying out the given task (left blank if no app was selected).
index TaskId WorkerId Query SelectedAppCount App0 App1 App2 App3 App4 ... 1111 24 315 Trixie Pet Toy 2 amazon google search 1167 33 228 Rhinoplasty surgery safety 2 google search youtube
Citation
@inproceedings{AliannejadiSigir18,
author = {Aliannejadi, Mohammad and Zamani, Hamed and Crestani, Fabio and Croft, W. Bruce},
title = {Target Apps Selection: Towards a Unified Search Framework for Mobile Devices},
booktitle = {Proceedings of the 41st International {ACM} {SIGIR} Conference on
Research and Development in Information Retrieval},
series = {{SIGIR'18}},
location = {Ann Arbor, Michigan, USA},
year = {2018}
}
